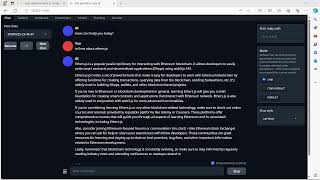
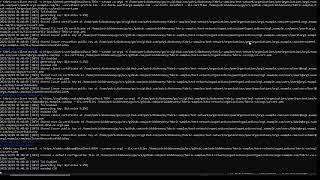
biomistral q2k q3km q8 comparison
Demo of performance for a medical scenario prompt with biomistral7b-Q_2_K, Q_K_M, and Q8. Q3_K_M is best for time and output quality in this test.
In a production environment a hospital might use GPT-4, BLOOM, or a larger parameter Mistral model. In the near future text gen, computer vision, and multi-modal models will approach 100% accuracy and instantaneous response time. Speed and accuracy won't be problems. Local hardware will be adequate for text gen, whereas cloud models will be necessary for digital twinning and other spatial use cases.
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Playlist UUY0xk_A4qJTQWcV2_3sqvJw · Patrick Devaney · 8 of 15
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 ▶
▶
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15

Penn Blockchain Hackathon Demo Oracle NFT Minter
Patrick Devaney
Demo Lionhacks NFT Based Content Authentication
Patrick Devaney
Aleo: Zero Knowledge Dapps - Blockchain at FIU
Patrick Devaney
Demoing a Large Language Model running locally on my laptop
Patrick Devaney
WizardCoder-1B Demo: Powerful Responsive Coding LLM at Home
Patrick Devaney
laser dolphin mixtral 2x7b dpo Q3 K M
Patrick Devaney
mixtral 2x7b Quantized 2 K prompt on machine learning
Patrick Devaney
biomistral q2k q3km q8 comparison
Patrick Devaney
SQLV2 Q4 demo
Patrick Devaney
Initializing a Hyperledger Fabric Blockchain with Docker and Ubuntu
Patrick Devaney
Finetune LLaMa 7b on RTX 3090 GPU - Tutorial
Patrick Devaney
Local InstantMesh Tiger
Patrick Devaney
groq swarms demo
Patrick Devaney
Rustifying My Repo With Swarms
Patrick Devaney
AI Agents Improve Your Code Step-by-Step | Groq + Gradio Demo
Patrick Devaney
Related AI Lessons
⚡
⚡
⚡
⚡
Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to AI
What happens when AI starts building itself
Dev.to AI
Ship Your SaaS for Free: OpenRouter’s Hidden Superpower
Dev.to AI
Shipping Multilingual Video with GPT-5.2: A Developer's Guide to VideoDubber's Translation Pipeline
Dev.to AI
🎓
Tutor Explanation
