Apache Iceberg V3 on Databricks: From Ingestion to Analytics
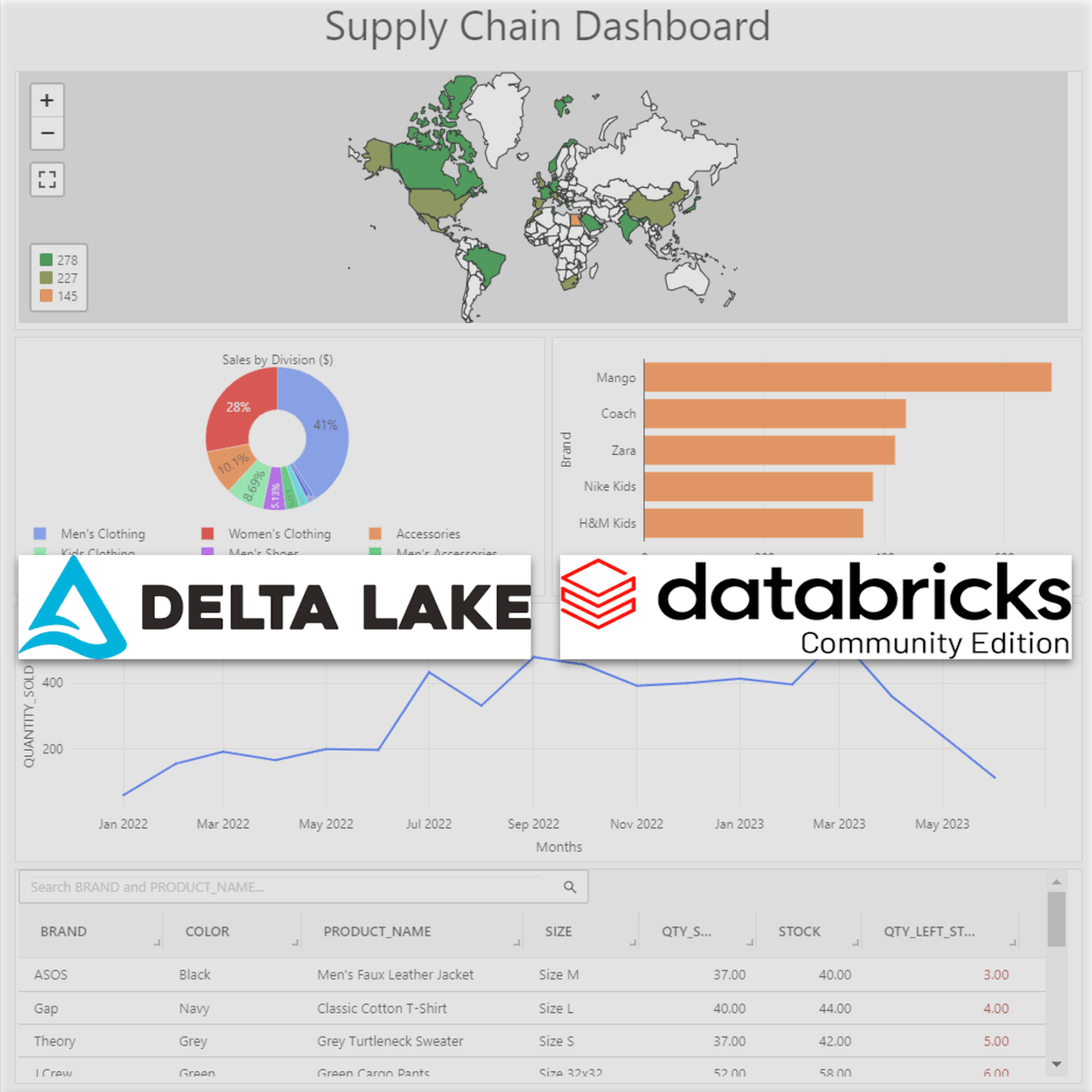
See what's possible with Iceberg V3 on Databricks — end to end. We'll ingest semi-structured JSON into an Iceberg V3 table using the new VARIANT column type, run concurrent writes with zero lock contention thanks to row-level concurrency, power a live AI/BI dashboard with incremental materialized views, and query the same data from vanilla open-source Spark via the Iceberg REST Catalog. No vendor lock-in, no data copying — just open formats governed by Unity Catalog.
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
More on: Data Warehousing
View skill →





🎓
Tutor Explanation
