Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Efficiency vs. Precision: A Python Deep Dive into Faster R-CNN and SSD PyTorch
In the rapidly evolving landscape of artificial intelligence, selecting the optimal architecture for computer vision is rarely a simple… Continue reading on Obj
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Dari Pixel ke AI: Bagaimana Komputer Memahami Sebuah Gambar
“Sebuah eksplorasi sederhana tentang bagaimana gambar digital diubah menjadi informasi yang dapat dipahami oleh Artificial Intelligence.”… Continue reading on M

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Teaching a Random Forest to Tell Walking from Running: A Computer Vision Pipeline with Hand-Built...
How a 56-feature baseline became a 240-feature classifier at 86% accuracy, with per-class SHAP guiding every feature engineering decision. Continue reading on M

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Mengenal Lebih Dekat Deteksi Tepi Canny Pada Pengolahan Citra Digital dengan python dan opencv
Dalam dunia pengolahan citra digital, mendeteksi batas suatu objek merupakan hal yang sangat penting. Continue reading on Medium »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 4
Add multi-camera support to a Python face recognition system using threaded OpenCV capture for faster, non-blocking real-time video Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 4
Add multi-camera support to a Python face recognition system using threaded OpenCV capture for faster, non-blocking real-time video Continue reading on Medium »

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Building an AI-Based Exam Monitoring System Using Computer Vision, YOLO, and OpenCV
Introduction Continue reading on Medium »

Dev.to · yqqwe
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Deconstructing the TikTok Media Stack: Building a High-Performance, No-Watermark Extraction Engine
Introduction As developers, we are often fascinated by how global-scale platforms manage...
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
1mo ago
Light Fields — Deep Dive + Problem: Set Matrix Zeroes
A daily deep dive into cv topics, coding problems, and platform features from PixelBank . Topic Deep Dive: Light Fields From the Image-Based Rendering chapter I

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1mo ago
IMPLEMENTING FASTER RCNN FROM SCRATCH IN PYTORCH FOR OBJECT DETECTION — PART ONE
Learning computer vision has been an exciting journey over the past few weeks. From data preprocessing to model evaluation, every new… Continue reading on Mediu
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How I Built a High-Precision AI Manga OCR Translator for Hardcore Readers
Most OCR tools are built for clean text. Receipts. Documents. Screenshots. Menus. Maybe a street sign if the lighting is kind. Manga is none of those things. A

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
What is Camera Calibration? How It Helps in Computer Vision Tasks
A ground truth guide to how cameras distort reality and why calibration is critical for accurate computer vision systems. Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
What is Camera Calibration? How It Helps in Computer Vision Tasks
A ground truth guide to how cameras distort reality and why calibration is critical for accurate computer vision systems. Continue reading on Medium »
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 2
Build real-time face recognition in Python with OpenCV, DeepFace, ArcFace embeddings, and live webcam-based identity matching. Continue reading on Medium »

Medium · AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Image Classification for AI: A Practical Guide for 2026
Practical guide to image classification for AI: learn how to manage datasets, ensure accuracy, and scale your computer vision projects. Continue reading on Medi
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Building Samaritan: A Multi-Camera Real-Time Face Recognition System in Python — Part 1
Build Samaritan, a Python real-time face recognition system using OpenCV, DeepFace, ArcFace, and multi-camera support. Continue reading on Medium »

Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The First Program Was Not Just Code
From algebra to execution: what the first program actually describes Continue reading on Level Up Coding »

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Is career in computer vision engineering a Dead-end ?
Until end of last year, despite LLMs on track for becoming world class SWE, I was still fairly confident about job security as a computer… Continue reading on M
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
AI photo tagging app
Introducing a newly released AI photo tagging app for the iphone. More details on our website ( https://siwave.io ) and a link to the kickstarter project. We we

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
From Factory Floor to Distributed System: Engineering a Real-Time Computer Vision Backend for…
Imagine you are on the floor of a battery manufacturing plant. Thousands of battery covers move down a conveyor every shift, each stamped… Continue reading on M

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
What Re-Learning C Taught Me About the Code I Write Every Day
Each weekend my younger brothers and I join a Discord call for our weekly game nights. Although the primary activity is gaming, a close… Continue reading on Cof
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
DeepID-Net: multi-stage and deformable deep convolutional neural networks forobject detection

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Revolutionizing Geospatial Data: Architecting Automated and Real-Time GeoAI Pipelines
Moving beyond static GIS to build predictive, event-driven spatial systems using advanced Computer Vision, streaming data, and edge… Continue reading on DataEng

Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Bilgisayarın Gözleri #2 — Görüntülerin Mutfağı: Pikseller, Matrisler ve Kanallar
Bir önceki bölümde görüntü işlemeye hızlı bir giriş yapmış ve OpenCV ile ilk fotoğrafımızı ekrana yansıtmıştık. “Bilgisayar görüntüyü… Continue reading on HUAWE
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Beyond Bounding Boxes: Achieving Cinematic Reframing via YOLOv11 Instance Segmentation
The transition from 16:9 landscape to 9:16 vertical video is often treated as a simple cropping problem. In most automated workflows, the… Continue reading on M
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Efficient Pipeline for Camera Trap Image Review

Medium · AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Computer Vision-Based Worker Safety Compliance
How AI Is Transforming Workplace Safety in Real Time Continue reading on Medium »
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Computer Vision-Based Worker Safety Compliance
How AI Is Transforming Workplace Safety in Real Time Continue reading on Medium »

Medium · Programming
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Tesseract for CAPTCHA Recognition: Not a Silver Bullet, But Effective in the Right Context
Using Tesseract to verify Captcha Code Continue reading on JIN System Architect »

Medium · AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The Bald Head That Broke Our AI (And What It Taught Me About Building Vision Systems That Actually…
Why physics-constrained computer vision is the gap between a demo that impresses and a system you can trust Continue reading on Medium »
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The Bald Head That Broke Our AI (And What It Taught Me About Building Vision Systems That Actually…
Why physics-constrained computer vision is the gap between a demo that impresses and a system you can trust Continue reading on Medium »
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Draw a Digit and Watch the Neural Network Think in Real Time
Introduction "A neural network can recognize digits" — but what's actually happening inside? I built a tool where you draw a digit with your finger or mouse, an

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Computer Vision vs Machine Learning: Key Differences Explained
If you’ve spent any time reading about AI, you’ve probably seen the terms “computer vision” and “machine learning” used almost… Continue reading on Artificial I
Medium · AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
CAMERA
Continue reading on Medium »
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Gaussian-SLAM: Photo-realistic Dense SLAM with Gaussian Splatting
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Facial Comparison's DNA Moment Is Here. Most Investigators Aren't Ready.
Is your investigative stack ready for the $26B identity shift? If you are a developer working in computer vision or digital forensics, you’re likely tracking th
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
ReflectCAP: Detailed Image Captioning with Reflective Memory
arXiv:2604.12357v1 Announce Type: new Abstract: Detailed image captioning demands both factual grounding and fine-grained coverage, yet existing methods have st
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
Intelligent ROI-Based Vehicle Counting Framework for Automated Traffic Monitoring
arXiv:2604.12470v1 Announce Type: new Abstract: Accurate vehicle counting through video surveillance is crucial for efficient traffic management. However, achie
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
2mo ago
ART-VITON: Measurement-Guided Latent Diffusion for Artifact-Free Virtual Try-On
arXiv:2509.25749v2 Announce Type: cross Abstract: Virtual try-on (VITON) aims to generate realistic images of a person wearing a target garment, requiring preci
OpenCV Blog
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How P&G Uses AI to Understand Human Behavior
Computer vision isn’t just for self-driving cars and robots. At Procter & Gamble, it’s helping researchers understand human behavior, generate synthetic data, a

Dev.to · Aman Shekhar
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The AI School Bus Camera Company Blanketing America in Tickets
Ever find yourself sitting in traffic, cursing under your breath because a school bus has stopped...
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
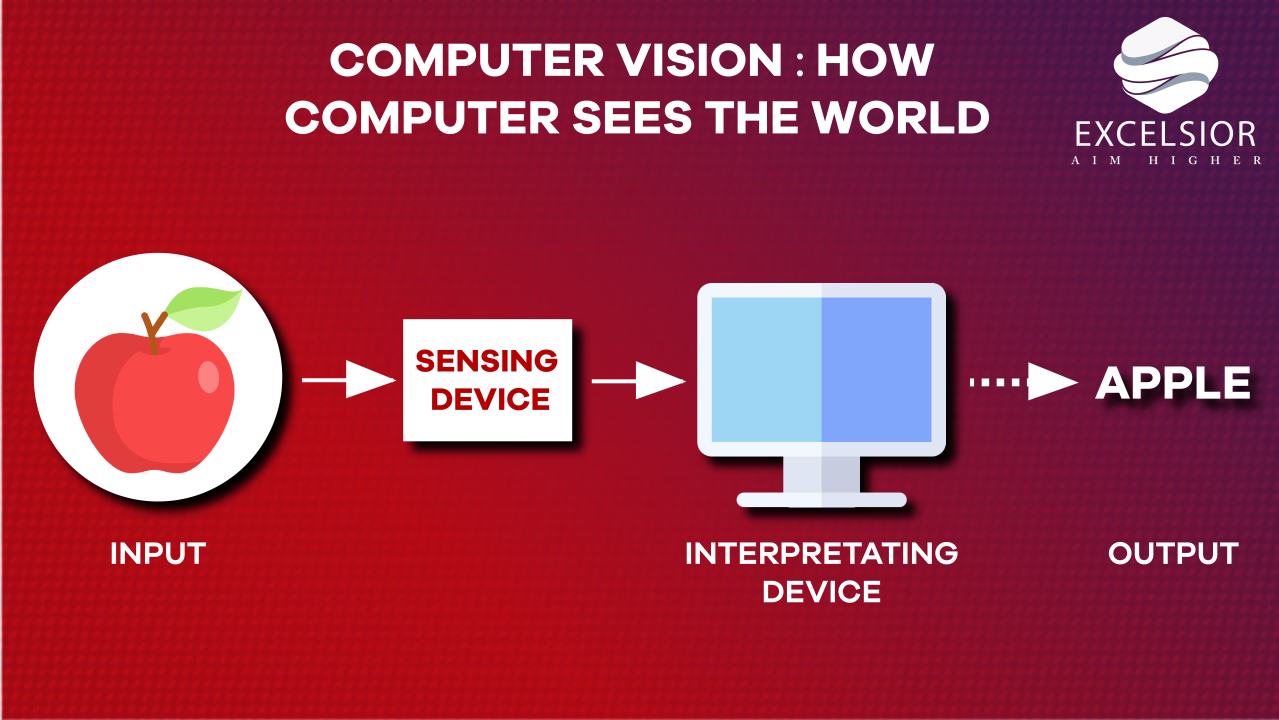
Computer Vision Explained - How Machines See the World.
Computer vision enables machines to interpret images using AI, powering healthcare, automation, security, and innovation. Continue reading on CodeToDeploy »
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
How to Run Vision AI Locally on Your Android Phone in 2026 (No Cloud, No Subscription)
Your phone has a camera and a processor powerful enough to run multimodal AI models. You can point it at a receipt, a document, a math problem, or anything else
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
2mo ago
CoPhIR: a Test Collection for Content-Based Image Retrieval

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Rethinking Smart Parking: A Dynamic Line and Box Approach to Computer Vision
Forget manual mapping and let dynamic model find the open spots for you. Continue reading on Medium »
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2mo ago
Rethinking Smart Parking: A Dynamic Line and Box Approach to Computer Vision
Forget manual mapping and let dynamic model find the open spots for you. Continue reading on Medium »
OpenCV Blog
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The Holographic Future Is Here. See It at OSCCA.
For decades, the hologram was a promise. A thing of science fiction. Something always just around the corner. Shawn Frayne decided to stop waiting. As co-founde

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2mo ago
The Fashion AI Dataset Landscape: Mapped by Task
A curated map of every major open dataset powering computer vision in fashion Continue reading on Medium »