📰 MarkTechPost
6 articles · Updated every 3 hours · View all reads
All
Articles 70,282Blog Posts 101,099Tech Tutorials 17,073Research Papers 14,962News 12,745
⚡ AI Lessons
MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
LlamaIndex Releases LiteParse: A CLI and TypeScript-Native Library for Spatial PDF Parsing in AI Agent Workflows
In the current landscape of Retrieval-Augmented Generation (RAG), the primary bottleneck for developers is no longer the large language model (LLM) itself, but

MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
Google Colab Now Has an Open-Source MCP (Model Context Protocol) Server: Use Colab Runtimes with GPUs from Any Local AI Agent
Google has officially released the Colab MCP Server, an implementation of the Model Context Protocol (MCP) that enables AI agents to interact directly with the
MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
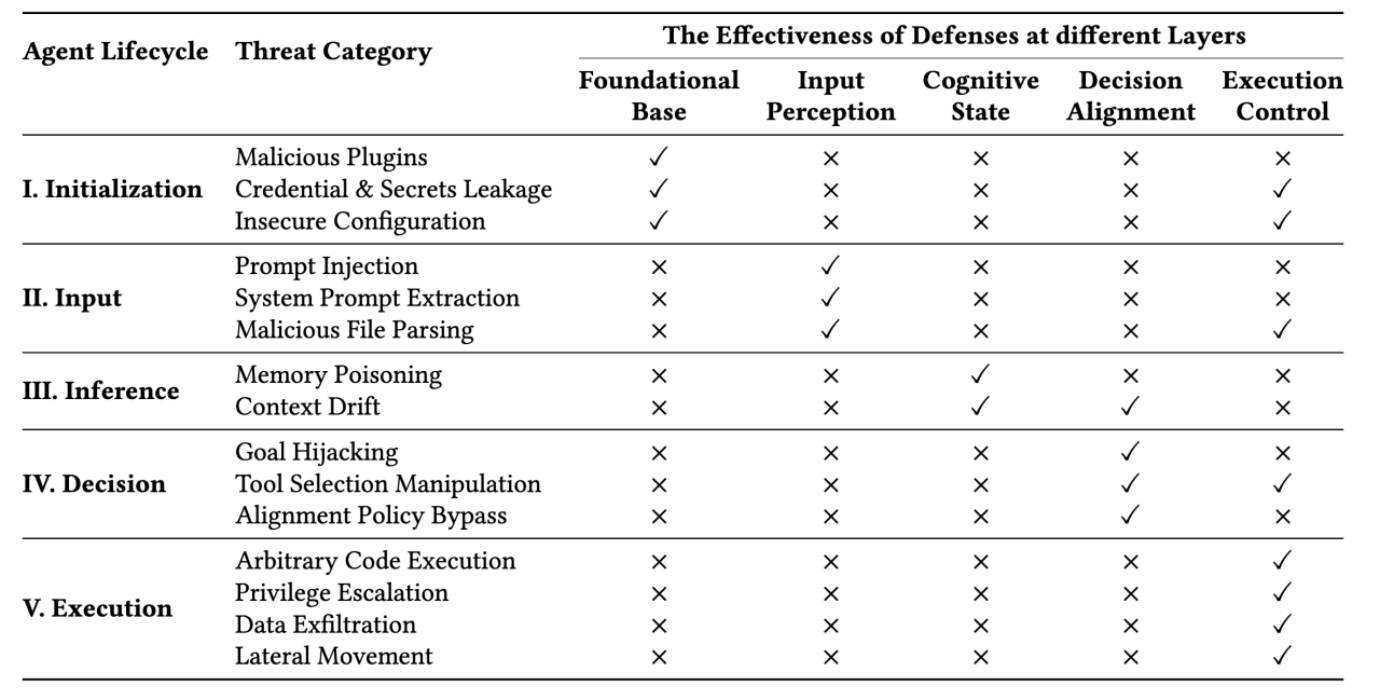
Tsinghua and Ant Group Researchers Unveil a Five-Layer Lifecycle-Oriented Security Framework to Mitigate Autonomous LLM Agent Vulnerabilities in OpenClaw
Autonomous LLM agents like OpenClaw are shifting the paradigm from passive assistants to proactive entities capable of executing complex, long-horizon tasks thr
MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
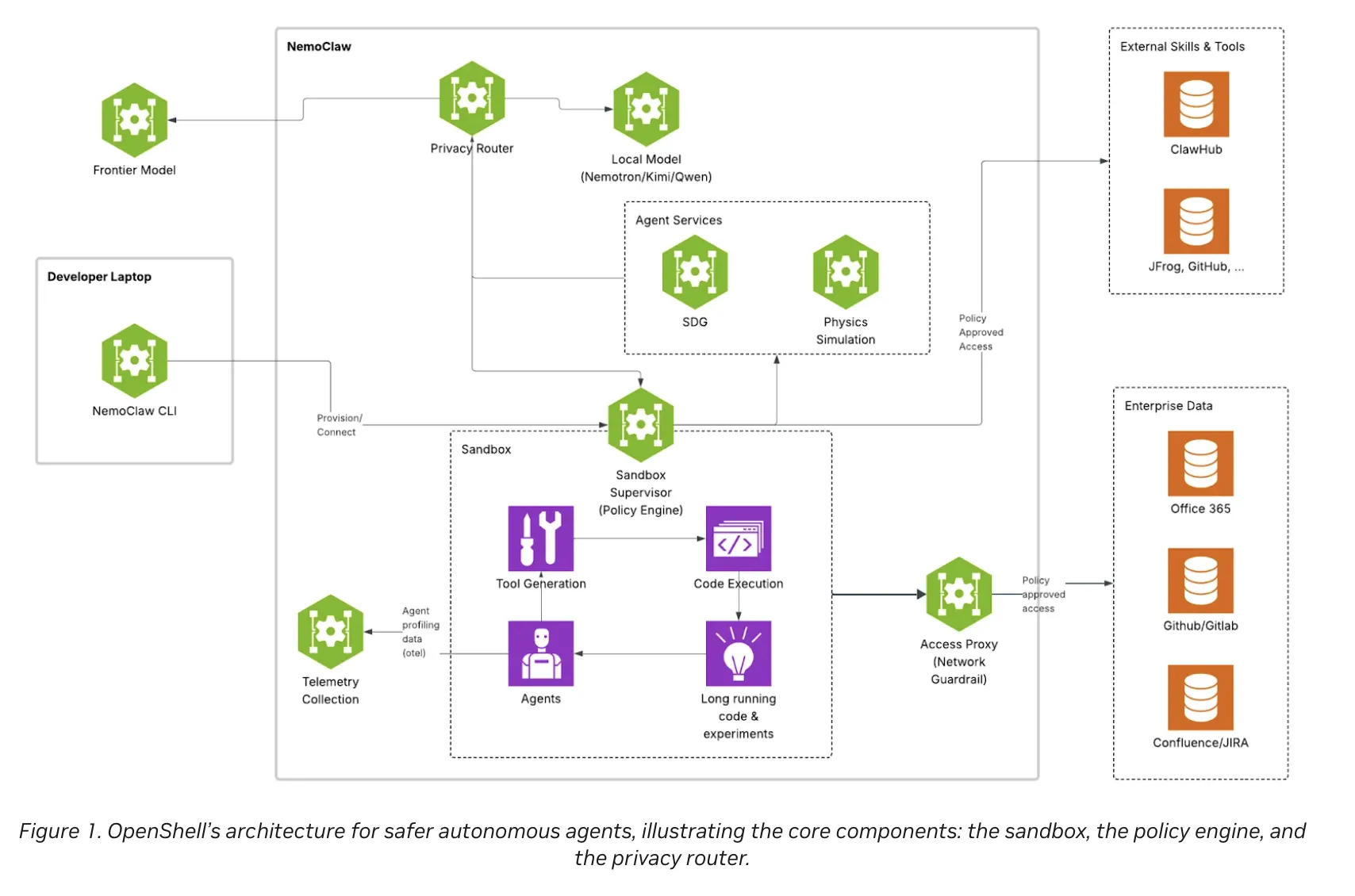
NVIDIA AI Open-Sources ‘OpenShell’: A Secure Runtime Environment for Autonomous AI Agents
The deployment of autonomous AI agents—systems capable of using tools and executing code—presents a unique security challenge. While standard LLM applications a
MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
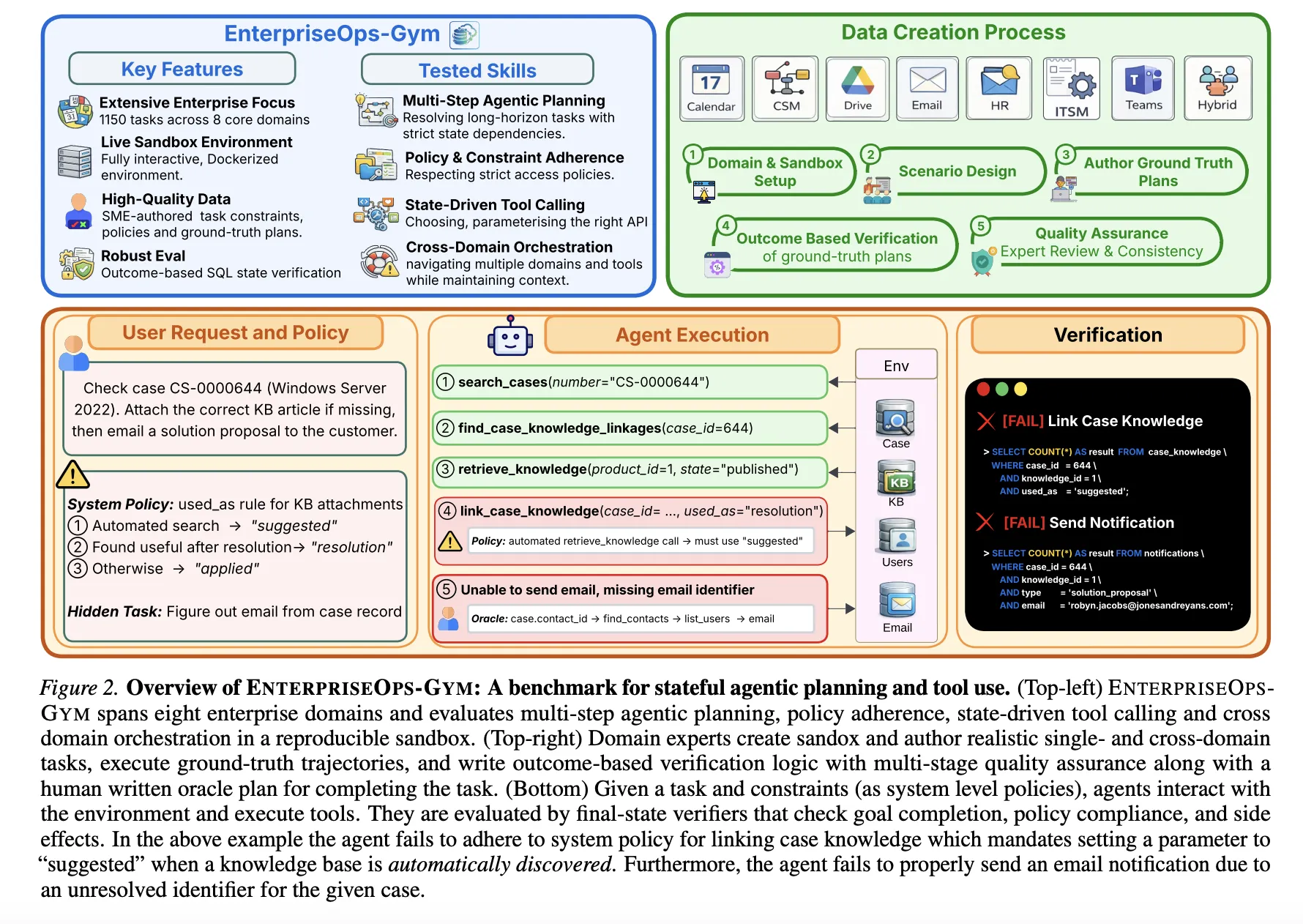
ServiceNow Research Introduces EnterpriseOps-Gym: A High-Fidelity Benchmark Designed to Evaluate Agentic Planning in Realistic Enterprise Settings
Large language models (LLMs) are transitioning from conversational to autonomous agents capable of executing complex professional workflows. However, their depl

MarkTechPost
🧠 Large Language Models
⚡ AI Lesson
2mo ago
Unsloth AI Releases Unsloth Studio: A Local No-Code Interface For High-Performance LLM Fine-Tuning With 70% Less VRAM Usage
The transition from a raw dataset to a fine-tuned Large Language Model (LLM) traditionally involves significant infrastructure overhead, including CUDA environm