What Is LLM Poisoning? Interesting Break Through
Skills:
AI Security90%
Key Takeaways
Explains LLM poisoning and its breakthrough in a joint study with Anthropic and UK AI Security Institute
Original Description
https://www.anthropic.com/research/small-samples-poison
In a joint study with the UK AI Security Institute and the Alan Turing Institute, we found that as few as 250 malicious documents can produce a "backdoor" vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents.
------------------------------------------------------------------------------------------------------
Festive offers are till Diwali .
On this festive offer we are providing 20% off on all our live courses. USE COUPON CODE AI20.
Enrollment link: https://www.krishnaik.in/liveclasses
https://www.krishnaik.in/liveclass2/ultimate-rag-bootcamp?id=7
Go ahead and utilize this opportunity.
Reach out to Krish Naik's counselling team on 📞 +919111533440 or +91 84848 37781 in case of any queries we are there to help you out.
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from Krish Naik · Krish Naik · 0 of 60
← Previous
Next →
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Natural Language Processing|Stemming
Krish Naik
Natural Language Processing|BagofWords
Krish Naik
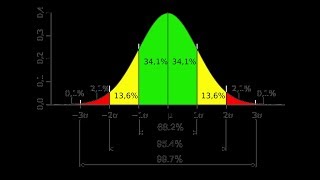
Gaussian distribution or Normal Distribution in statisctics
Krish Naik
Natural Language Processing|TF-IDF for Machine Learning| Text Prerocessing
Krish Naik
Log Normal Distribution in Statistics
Krish Naik
Covariance in Statistics
Krish Naik
Confusion matrix, Precision, Recall| Data Science Interview questions
Krish Naik
Tutorial 44-Balanced vs Imbalanced Dataset and how to handle Imbalanced Dataset
Krish Naik
Implementing a Spam classifier in python| Natural Language Processing
Krish Naik
Tutorial 11-Exploratory Data Analysis(EDA) of Titanic dataset
Krish Naik
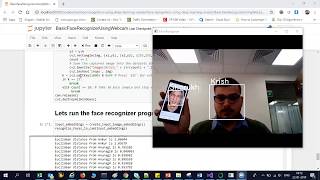
Face Recognition using open CV and VGG 16 Transfer Learning
Krish Naik
Pedestrian Detection using OpenCV from Videos
Krish Naik
Face and Eye Detection from Videos using HAAR Cascade Classifier
Krish Naik
Reading, Writing and Displaying images with Opencv| OpenCV Tutorial
Krish Naik
OpenCV Installation | OpenCV tutorial
Krish Naik
Face and Eye Detection from Images using HAAR Cascade Classifier
Krish Naik
Car Detection using HAAR Cascade and Opencv from Videos.
Krish Naik
Using OpenFace for Face recognition in Keras
Krish Naik
OpenPose Tutorial with Tensorflow
Krish Naik
Multiple Linear Regression using python and sklearn
Krish Naik
Dimensional Reduction| Principal Component Analysis
Krish Naik
Movie Recommender System using Python
Krish Naik
TPR,FPR,FNR,TNR, Confusion Matrix
Krish Naik
Precision, Recall and F1-Score
Krish Naik
Artificial Neural Network for Customer's Exit Prediction from Bank
Krish Naik
GridSearchCV- Select the best hyperparameter for any Classification Model
Krish Naik
RandomizedSearchCV- Select the best hyperparameter for any Classification Model
Krish Naik
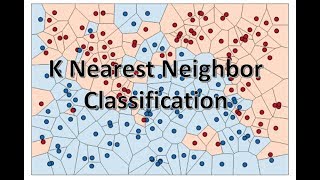
K Nearest Neighbor classification with Intuition and practical solution
Krish Naik
K Means Clustering Intuition
Krish Naik
Create custom Alexa Skill- Lambda function- Part2
Krish Naik
Hierarchical Clustering intuition
Krish Naik
Implement Transfer Learning with a generic Code Template
Krish Naik
Gender Classifier and Age Estimator using Resnet Convolution Neural Network
Krish Naik
Unlock Your Application With Your Face using OpenCV
Krish Naik
Draw rectangle from webcam and sketch process it on a live feed
Krish Naik
Complete Life Cycle of a Data Science Project
Krish Naik
How we can apply Machine Learning in Finance
Krish Naik
Deep Learning in Medical Science
Krish Naik
How to switch your career to Data Science.
Krish Naik
Linear Regression Mathematical Intuition
Krish Naik
Handle Categorical features using Python
Krish Naik
Machine Learning Algorithm- Which one to choose for your Problem?
Krish Naik
DBSCAN Clustering Easily Explained with Implementation
Krish Naik
Curse of Dimensionality Easily explained| Machine Learning
Krish Naik
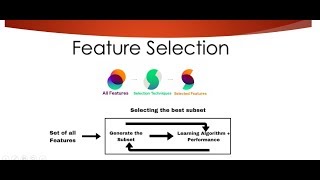
Feature Selection Techniques Easily Explained | Machine Learning
Krish Naik
Tutorial 29-R square and Adjusted R square Clearly Explained| Machine Learning
Krish Naik
Cross Validation using sklearn and python | Machine Learning
Krish Naik
Handling Missing Data Easily Explained| Machine Learning
Krish Naik
Deploy Machine Learning Model using Flask
Krish Naik
Deployment of Deep Learning Model using Flask
Krish Naik
How to Visualize Multiple Linear Regression in python
Krish Naik
K Nearest Neighbour Easily Explained with Implementation
Krish Naik
Predicting Heart Disease using Machine Learning
Krish Naik
Predicting Lungs Disease using Deep Learning
Krish Naik
Stock Sentiment Analysis using News Headlines
Krish Naik
Random Forest(Bootstrap Aggregation) Easily Explained
Krish Naik
Voting Classifier(Hard Voting and Soft Voting Classifier)
Krish Naik
Credit Card Fraud Detection using Machine Learning from Kaggle
Krish Naik
Hyperparameter Optimization for Xgboost
Krish Naik
Tutorial 45-Handling imbalanced Dataset using python- Part 1
Krish Naik
More on: AI Security
View skill →








Related Reads
📰
📰
📰
📰
Building Production-Grade LLM Evaluation Pipelines: From Vibes to Metrics
Dev.to AI
Why Every AI Engineer Should Learn Hugging Face
Medium · Machine Learning
A bug in Qwen3-TTS taught me voice is biometric
Dev.to · Daniel Nwaneri
What is LoRA and how it lets anyone fine-tune a massive AI model on a single GPU
Medium · LLM
🎓
Tutor Explanation
