Learn Multi AI Agent Systems with crewAI: Lesson 1
Skills:
Multi-Agent Systems90%
Enroll in the full course 👉 https://bit.ly/3K9y1u4
Multi AI Agent Workflows with CrewAI is taught by João Moura, founder and CEO of crewAI, and it will teach you key principles of designing effective AI agents and how to organize a team of agents to perform complex, multi-step tasks.
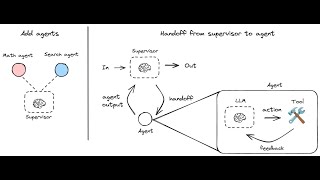
Explore key components of multi-agent systems:
- Role-playing: Assign specialized roles to agents
- Memory: Provide agents with short-term, long-term, and shared memory
- Tools: Assign pre-built and custom tools to each agent (e.g. for web search)
- Focus: Break down the tasks, goals, and tools and assign multiple AI agents for better performance
- Guardrails: Effectively handle errors, hallucinations, and infinite loops
- Cooperation: Perform tasks in series, in parallel, and hierarchically
Work with crewAI, an open source library designed for building multi-agent systems, and get hands-on by building agent crews that execute common business processes, such as:
- Tailor resumes and interview prep for job applications
- Research, write, and edit technical articles
- Automate customer support inquiries
- Conduct customer outreach campaigns
- Plan and execute events
- Perform financial analysis
If you've taken some prompt engineering courses and want to incorporate LLMs in your professional work, then this course is designed for you.
Enroll in the full course 👉 https://bit.ly/3K9y1u4
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Uploads from DeepLearningAI · DeepLearningAI · 0 of 60
← Previous
Next →
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 11
11
 12
12
 13
13
 14
14
 15
15
 16
16
 17
17
 18
18
 19
19
 20
20
 21
21
 22
22
 23
23
 24
24
 25
25
 26
26
 27
27
 28
28
 29
29
 30
30
 31
31
 32
32
 33
33
 34
34
 35
35
 36
36
 37
37
 38
38
 39
39
 40
40
 41
41
 42
42
 43
43
 44
44
 45
45
 46
46
 47
47
 48
48
 49
49
 50
50
 51
51
 52
52
 53
53
 54
54
 55
55
 56
56
 57
57
 58
58
 59
59
 60
60

Forward and Backward Propagation (C1W4L06)
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Yuanqing Lin
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Ruslan Salakhutdinov
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Yoshua Bengio
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Pieter Abbeel
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Ian Goodfellow
DeepLearningAI
deeplearning.ai's Heroes of Deep Learning: Andrej Karpathy
DeepLearningAI
Using an Appropriate Scale (C2W3L02)
DeepLearningAI
Gradient Checking (C2W1L13)
DeepLearningAI
Gradient Checking Implementation Notes (C2W1L14)
DeepLearningAI
Learning Rate Decay (C2W2L09)
DeepLearningAI
Understanding Mini-Batch Gradient Dexcent (C2W2L02)
DeepLearningAI
Mini Batch Gradient Descent (C2W2L01)
DeepLearningAI
The Problem of Local Optima (C2W3L10)
DeepLearningAI
Exponentially Weighted Averages (C2W2L03)
DeepLearningAI
Tuning Process (C2W3L01)
DeepLearningAI
Understanding Exponentially Weighted Averages (C2W2L04)
DeepLearningAI
Bias Correction of Exponentially Weighted Averages (C2W2L05)
DeepLearningAI
Gradient Descent With Momentum (C2W2L06)
DeepLearningAI
Normalizing Activations in a Network (C2W3L04)
DeepLearningAI
Hyperparameter Tuning in Practice (C2W3L03)
DeepLearningAI
Adam Optimization Algorithm (C2W2L08)
DeepLearningAI
RMSProp (C2W2L07)
DeepLearningAI
Fitting Batch Norm Into Neural Networks (C2W3L05)
DeepLearningAI
Why Does Batch Norm Work? (C2W3L06)
DeepLearningAI
Batch Norm At Test Time (C2W3L07)
DeepLearningAI
Softmax Regression (C2W3L08)
DeepLearningAI
Deep Learning Frameworks (C2W3L10)
DeepLearningAI
Neural Network Overview (C1W3L01)
DeepLearningAI
Training Softmax Classifier (C2W3L09)
DeepLearningAI
Why Deep Representations? (C1W4L04)
DeepLearningAI
Gradient Descent For Neural Networks (C1W3L09)
DeepLearningAI
Neural Network Representations (C1W3L02)
DeepLearningAI
TensorFlow (C2W3L11)
DeepLearningAI
Activation Functions (C1W3L06)
DeepLearningAI
Explanation For Vectorized Implementation (C1W3L05)
DeepLearningAI
Getting Matrix Dimensions Right (C1W4L03)
DeepLearningAI
Understanding Dropout (C2W1L07)
DeepLearningAI
Building Blocks of a Deep Neural Network (C1W4L05)
DeepLearningAI
Why Non-linear Activation Functions (C1W3L07)
DeepLearningAI
Computing Neural Network Output (C1W3L03)
DeepLearningAI
Backpropagation Intuition (C1W3L10)
DeepLearningAI
Train/Dev/Test Sets (C2W1L01)
DeepLearningAI
Deep L-Layer Neural Network (C1W4L01)
DeepLearningAI
Random Initialization (C1W3L11)
DeepLearningAI
Other Regularization Methods (C2W1L08)
DeepLearningAI
Normalizing Inputs (C2W1L09)
DeepLearningAI
Derivatives Of Activation Functions (C1W3L08)
DeepLearningAI
Parameters vs Hyperparameters (C1W4L07)
DeepLearningAI
Vectorizing Across Multiple Examples (C1W3L04)
DeepLearningAI
What does this have to do with the brain? (C1W4L08)
DeepLearningAI
Dropout Regularization (C2W1L06)
DeepLearningAI
Vanishing/Exploding Gradients (C2W1L10)
DeepLearningAI
Basic Recipe for Machine Learning (C2W1L03)
DeepLearningAI
Bias/Variance (C2W1L02)
DeepLearningAI
Forward Propagation in a Deep Network (C1W4L02)
DeepLearningAI
Weight Initialization in a Deep Network (C2W1L11)
DeepLearningAI
Numerical Approximations of Gradients (C2W1L12)
DeepLearningAI
Regularization (C2W1L04)
DeepLearningAI
Why Regularization Reduces Overfitting (C2W1L05)
DeepLearningAI
More on: Multi-Agent Systems
View skill →








Related AI Lessons
⚡
⚡
⚡
⚡
Meta Crashed My Server to Train Their Ai. 110 People Said It Happened to Them Too.
Medium · Startup
How Agentic AI Is Transforming Hiring in 2026
Medium · Startup
I Replaced My $60,000 Operations Budget With Three AI Systems. Here Is Exactly What I Did.
Medium · Startup
When AI Gets Stuck in Its Own Loop: The Autonomous Sunk-Cost Fallacy
Medium · ChatGPT
🎓
Tutor Explanation
