TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Learn about TIPSv2, a next-generation vision-language pretraining model that advances patch-text alignment with enhanced techniques, and how it achieves strong performance across numerous multimodal and vision tasks.
- Investigate the TIPSv2 pretraining process and its three key changes: iBOT++, Head-only EMA, and Multi-Granularity Captions.
- Apply the TIPSv2 model to various multimodal and vision tasks to evaluate its performance.
- Use the provided GitHub repository and Colab notebooks to experiment with TIPSv2 and explore its capabilities.
- Compare the results of TIPSv2 with other recent vision encoder models to understand its strengths and weaknesses.
- Explore the applications of TIPSv2 in areas such as zero-shot segmentation and semantic focus.
This article is relevant to AI researchers and engineers working on vision-language models, particularly those interested in pretraining techniques and multimodal learning. The team can benefit from understanding the improvements and applications of TIPSv2.
💡 TIPSv2 achieves strong performance across numerous tasks and datasets by introducing improved pretraining techniques, including iBOT++, Head-only EMA, and Multi-Granularity Captions.
🚀 TIPSv2: Next-gen vision-language pretraining with enhanced patch-text alignment! 🤖💻 #AI #VisionLanguage #MultimodalLearning
Key Takeaways
Learn about TIPSv2, a next-generation vision-language pretraining model that advances patch-text alignment with enhanced techniques, and how it achieves strong performance across numerous multimodal and vision tasks.
Full Article
URL Source: https://gdm-tipsv2.github.io/
Published Time: Wed, 15 Apr 2026 00:42:13 GMT
Markdown Content:
# TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
# TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
[Bingyi Cao](https://scholar.google.com/citations?user=7EeSOcgAAAAJ&hl=en&oi=ao)*[Koert Chen](https://scholar.google.com/citations?user=swG8fpkAAAAJ&hl=en&oi=ao)*[Kevis-Kokitsi Maninis](https://www.kmaninis.com/)[Kaifeng Chen](https://scholar.google.com/citations?user=xjEcoNQAAAAJ&hl=en&oi=ao)1[Arjun Karpur](https://scholar.google.com/citations?user=jgSItF4AAAAJ&hl=en&oi=ao)2[Ye Xia](https://scholar.google.com/citations?user=QQhJ1pAAAAAJ&hl=en&oi=ao)[Sahil Dua](https://www.sahildua.com/)[Tanmaya Dabral](https://www.vanillabug.com/)[Guangxing Han](https://scholar.google.com/citations?user=1dh5WWUAAAAJ&hl=en&oi=ao)[Bohyung Han](https://cv.snu.ac.kr/index.php/bhhan/)3[Joshua Ainslie](https://scholar.google.com/citations?user=3zlZ6n8AAAAJ)[Alex Bewley](https://bewley.ai/)[Mithun Jacob](https://scholar.google.com/citations?user=YEplDTkAAAAJ&hl=en&oi=ao)[Rene Wagner](https://scholar.google.com/citations?user=myJWQxwAAAAJ)[Washington Ramos](https://homepages.dcc.ufmg.br/~washington.ramos/)4[Krzysztof Choromanski](https://scholar.google.com/citations?user=J8OgouwAAAAJ&hl=en)[Mojtaba Seyedhosseini](https://scholar.google.com/citations?user=U8bXgtkAAAAJ&hl=en&oi=ao)[Howard Zhou](https://scholar.google.com/citations?user=Rh9T3EcAAAAJ&hl=en/)[Andre Araujo](https://andrefaraujo.github.io//)
Google DeepMind
* Equal contribution
now at: 1 xAI 2 Epsilon Health 3 Seoul National University 4 Google
CVPR 2026
[Paper](https://arxiv.org/abs/2604.12012)[GitHub](https://github.com/google-deepmind/tips)[Checkpoints](https://github.com/google-deepmind/tips?tab=readme-ov-file#tipsv2-models)[Colab](https://github.com/google-deepmind/tips?tab=readme-ov-file#demos-and-notebooks)[HF Demo](https://huggingface.co/spaces/google/TIPSv2)[HF Models](https://huggingface.co/collections/google/tipsv2)
## Overview
TIPSv2 is the next generation of the [TIPS](https://gdm-tips.github.io/) family of foundational image-text encoders empowering strong performance across numerous multimodal and vision tasks. Our work starts by revealing a surprising finding, where distillation unlocks superior patch-text alignment over standard pretraining, leading to distilled student models significantly surpassing their much larger teachers in this capability. We carefully investigate this phenomenon, leading to an improved pretraining recipe that upgrades our vision-language encoder significantly. Three key changes are introduced to our pretraining process (illustrated in the figure below): **iBOT++** extends the patch-level self-supervised loss to all tokens for stronger dense alignment; **Head-only EMA** reduces training cost while retaining performance; and **Multi-Granularity Captions** uses PaliGemma and Gemini descriptions for richer text supervision. Combining these components, TIPSv2 demonstrates strong performance across 9 tasks and 20 datasets, generally on par with or better than recent vision encoder models, with particularly strong gains in zero-shot segmentation.
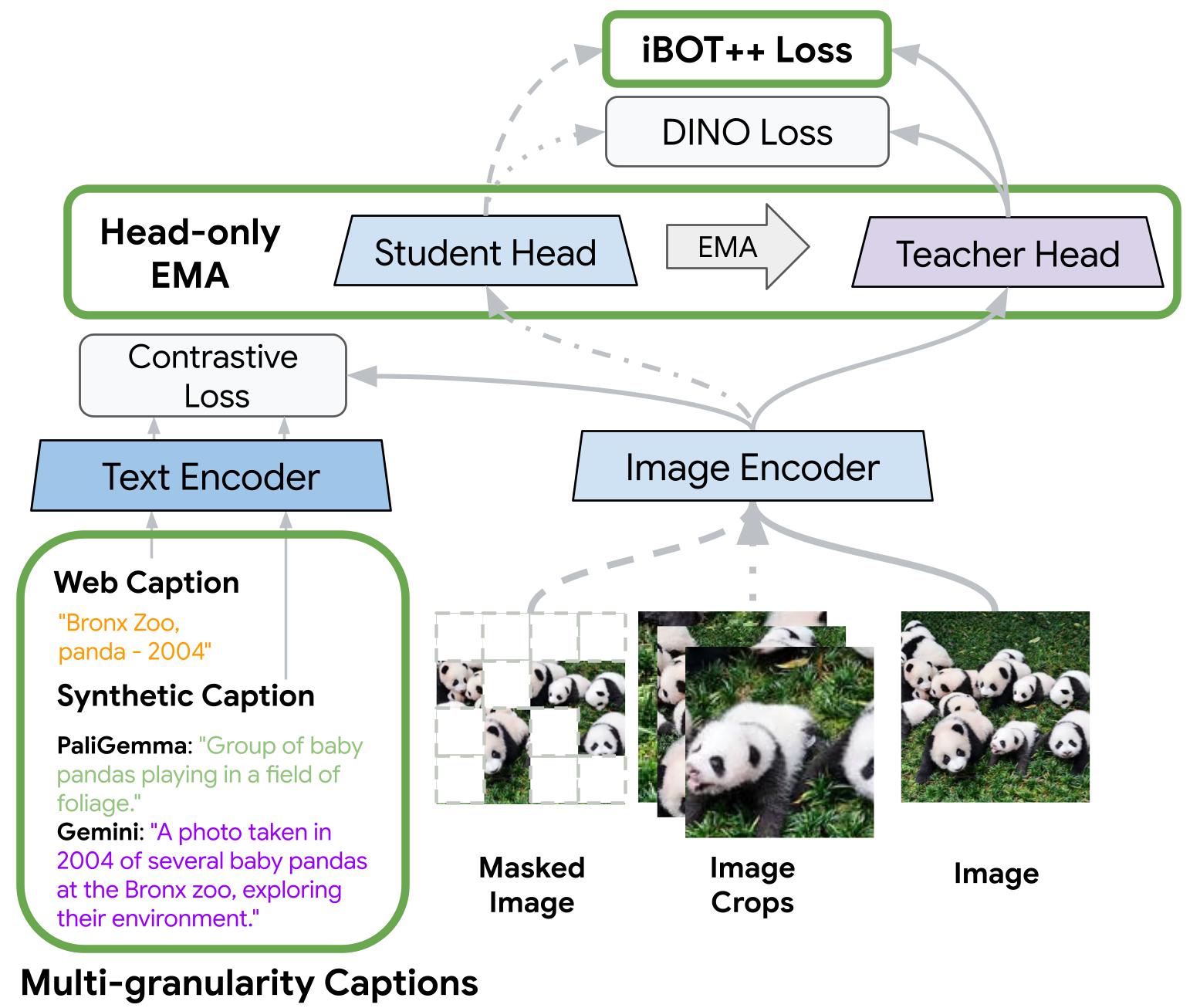
**TIPSv2 pretraining overview.** TIPSv2 introduces 3 pretraining improvements: **iBOT++** (enhanced MIM loss), **Head-only EMA** (memory-efficient self-supervised losses), and **Multi-granularity captions** (richer text supervision).
## Visualization
### PCA Feature Maps
TIPSv2 produces smoother feature maps with well-delineated objects compared to prior vision-language models (e.g., TIPS and SigLIP2). While DINOv3 also exhibits smooth feature maps, TIPSv2 shows stronger **semantic focus**: object boundaries are more precisely delineated and re





