microsoft/VibeVoice
📰 Simon Willison's Blog
Learn to use Microsoft's VibeVoice for speech-to-text tasks with speaker diarization, and apply it to real-world audio files using the mlx-audio tool.
Action Steps
- Install the mlx-audio tool and download the VibeVoice-ASR-4bit model
- Run the uv command with mlx-audio to generate speech-to-text transcripts
- Configure the command with options such as --max-tokens to handle longer audio files
- Test the tool with different audio file formats such as .wav and .mp3
- Use Datasette Lite to browse and explore the resulting JSON transcript
Who Needs to Know This
Developers and data scientists on a team can benefit from using VibeVoice for speech-to-text tasks, especially when working with audio data that requires speaker diarization.
Key Insight
💡 VibeVoice can handle up to an hour of audio and provides speaker diarization, making it a useful tool for speech-to-text tasks.
Share This
🗣️ Try Microsoft's VibeVoice for speech-to-text with speaker diarization! 📊
Key Takeaways
Learn to use Microsoft's VibeVoice for speech-to-text tasks with speaker diarization, and apply it to real-world audio files using the mlx-audio tool.
Full Article
Title: microsoft/VibeVoice
URL Source: https://simonwillison.net/2026/Apr/27/vibevoice/
Published Time: Mon, 27 Apr 2026 23:53:07 GMT
Markdown Content:
# microsoft/VibeVoice
# [Simon Willison’s Weblog](https://simonwillison.net/)
[Subscribe](https://simonwillison.net/about/#subscribe)
**Sponsored by:** Sonar — Now with SAST + SCA for secure, dependency-aware Agentic Engineering. [SonarQube Advanced Security](https://fandf.co/4bzyODl)
27th April 2026 - Link Blog
**[microsoft/VibeVoice](https://github.com/microsoft/VibeVoice)**. VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model.
Microsoft released it on January 21st, 2026 but I hadn't tried it until today. Here's a one-liner to run it on a Mac with `uv`, [mlx-audio](https://github.com/Blaizzy/mlx-audio) (by Prince Canuma) and the 5.71GB [mlx-community/VibeVoice-ASR-4bit](https://huggingface.co/mlx-community/VibeVoice-ASR-4bit) MLX conversion of the [17.3GB VibeVoice-ASR](https://huggingface.co/microsoft/VibeVoice-ASR/tree/main) model, in this case against a downloaded copy of my recent [podcast appearance with Lenny Rachitsky](https://simonwillison.net/2026/Apr/2/lennys-podcast/):
```
uv run --with mlx-audio python -m mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
```
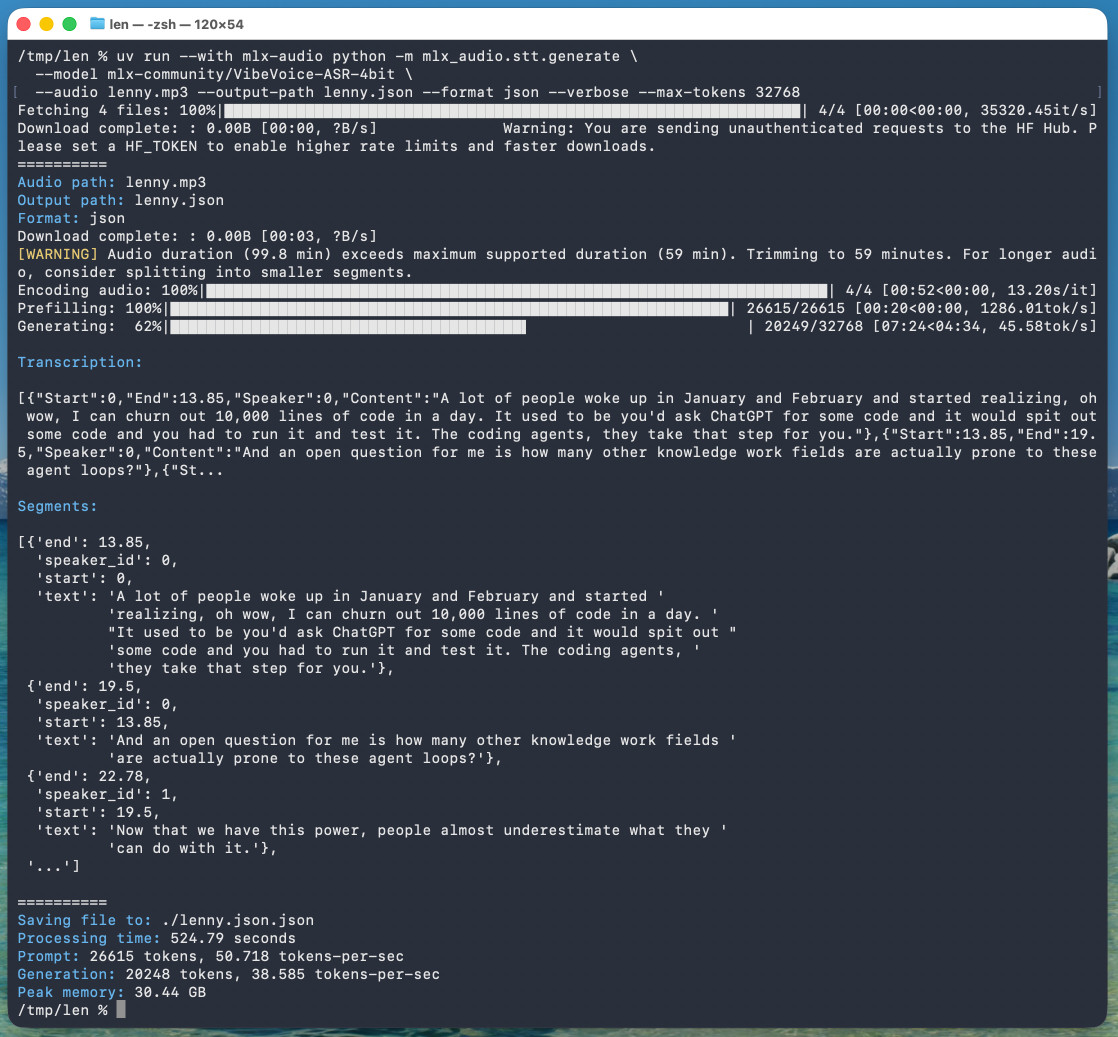
The tool reported back:
```
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
```
So that's 8 minutes 45 seconds for an hour of audio (running on a 128GB M5 Max MacBook Pro).
I've tested it against `.wav` and `.mp3` files and they both worked fine.
If you omit `--max-tokens` it defaults to 8192, which is enough for about 25 minutes of audio. I discovered that through trial-and-error and quadrupled it to guarantee I'd get the full hour.
That command reported using 30.44GB of RAM at peak, but in Activity Monitor I observed 61.5GB of usage during the prefill stage and around 18GB during the generating phase.
Here's [the resulting JSON](https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f). The key structure looks like this:
```
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
```
Since that's an array of objects we can [open it in Datasette Lite](https://lite.datasette.io/?json=https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f#/data/raw?_facet=speaker_id), making it easier to browse.
Amusingly that Datasette Lite view shows three speakers - it identified Lenny and me for the conversation, and then a separate Lenny for the voice he used for the additional intro and the sponsor reads!
VibeVoice can only handle up to an hour of audi
URL Source: https://simonwillison.net/2026/Apr/27/vibevoice/
Published Time: Mon, 27 Apr 2026 23:53:07 GMT
Markdown Content:
# microsoft/VibeVoice
# [Simon Willison’s Weblog](https://simonwillison.net/)
[Subscribe](https://simonwillison.net/about/#subscribe)
**Sponsored by:** Sonar — Now with SAST + SCA for secure, dependency-aware Agentic Engineering. [SonarQube Advanced Security](https://fandf.co/4bzyODl)
27th April 2026 - Link Blog
**[microsoft/VibeVoice](https://github.com/microsoft/VibeVoice)**. VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model.
Microsoft released it on January 21st, 2026 but I hadn't tried it until today. Here's a one-liner to run it on a Mac with `uv`, [mlx-audio](https://github.com/Blaizzy/mlx-audio) (by Prince Canuma) and the 5.71GB [mlx-community/VibeVoice-ASR-4bit](https://huggingface.co/mlx-community/VibeVoice-ASR-4bit) MLX conversion of the [17.3GB VibeVoice-ASR](https://huggingface.co/microsoft/VibeVoice-ASR/tree/main) model, in this case against a downloaded copy of my recent [podcast appearance with Lenny Rachitsky](https://simonwillison.net/2026/Apr/2/lennys-podcast/):
```
uv run --with mlx-audio python -m mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
```

The tool reported back:
```
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
```
So that's 8 minutes 45 seconds for an hour of audio (running on a 128GB M5 Max MacBook Pro).
I've tested it against `.wav` and `.mp3` files and they both worked fine.
If you omit `--max-tokens` it defaults to 8192, which is enough for about 25 minutes of audio. I discovered that through trial-and-error and quadrupled it to guarantee I'd get the full hour.
That command reported using 30.44GB of RAM at peak, but in Activity Monitor I observed 61.5GB of usage during the prefill stage and around 18GB during the generating phase.
Here's [the resulting JSON](https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f). The key structure looks like this:
```
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
```
Since that's an array of objects we can [open it in Datasette Lite](https://lite.datasette.io/?json=https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f#/data/raw?_facet=speaker_id), making it easier to browse.
Amusingly that Datasette Lite view shows three speakers - it identified Lenny and me for the conversation, and then a separate Lenny for the voice he used for the additional intro and the sponsor reads!
VibeVoice can only handle up to an hour of audi