LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification
📰 ArXiv cs.AI
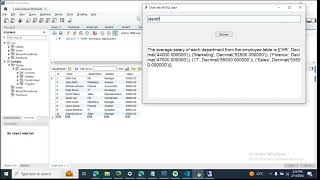
LongSpec is a lossless speculative decoding method for Large Language Models with long contexts
Action Steps
- Understand the limitations of current speculative decoding methods for LLMs
- Implement LongSpec's efficient drafting and verification techniques to accelerate inference
- Evaluate the performance of LongSpec on various LLM applications, such as LLM agents
Who Needs to Know This
ML researchers and AI engineers can benefit from LongSpec to improve the efficiency of LLMs, especially for applications like LLM agents
Key Insight
💡 LongSpec enables efficient inference over long contexts for LLMs without sacrificing accuracy
Share This
💡 LongSpec: efficient lossless speculative decoding for LLMs with long contexts
Key Takeaways
LongSpec is a lossless speculative decoding method for Large Language Models with long contexts
Full Article
Title: LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification
Abstract:
arXiv:2502.17421v3 Announce Type: replace-cross Abstract: As Large Language Models (LLMs) can now process extremely long contexts, efficient inference over these extended inputs has become increasingly important, especially for emerging applications like LLM agents that highly depend on this capability. Speculative decoding (SD) offers a promising lossless acceleration technique compared to lossy alternatives such as quantization and model cascades. However, most state-of-the-art SD methods are
Abstract:
arXiv:2502.17421v3 Announce Type: replace-cross Abstract: As Large Language Models (LLMs) can now process extremely long contexts, efficient inference over these extended inputs has become increasingly important, especially for emerging applications like LLM agents that highly depend on this capability. Speculative decoding (SD) offers a promising lossless acceleration technique compared to lossy alternatives such as quantization and model cascades. However, most state-of-the-art SD methods are