EVPO: Explained Variance Policy Optimization for Adaptive Critic Utilization in LLM Post-Training
📰 ArXiv cs.AI
Learn how to optimize LLM post-training using EVPO, a novel approach that balances critic-based and critic-free methods for adaptive variance reduction
Action Steps
- Implement EVPO algorithm to optimize policy in LLM post-training
- Compare performance of EVPO with classical critic-based methods like PPO
- Evaluate the impact of estimation noise on variance reduction in sparse-reward settings
- Apply EVPO to real-world LLM post-training tasks to assess its effectiveness
- Analyze the trade-offs between critic-based and critic-free methods in EVPO
Who Needs to Know This
Researchers and engineers working on LLM post-training and reinforcement learning can benefit from this approach to improve the efficiency and effectiveness of their models
Key Insight
💡 EVPO balances the benefits of critic-based and critic-free methods to achieve efficient variance reduction in sparse-reward settings
Share This
🚀 Introducing EVPO: a novel approach for adaptive critic utilization in LLM post-training! 🤖
Key Takeaways
Learn how to optimize LLM post-training using EVPO, a novel approach that balances critic-based and critic-free methods for adaptive variance reduction
Full Article
Title: EVPO: Explained Variance Policy Optimization for Adaptive Critic Utilization in LLM Post-Training
Abstract:
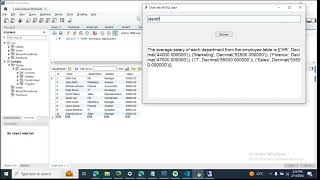
arXiv:2604.19485v1 Announce Type: cross Abstract: Reinforcement learning (RL) for LLM post-training faces a fundamental design choice: whether to use a learned critic as a baseline for policy optimization. Classical theory favors critic-based methods such as PPO for variance reduction, yet critic-free alternatives like GRPO have gained widespread adoption due to their simplicity and competitive performance. We show that in sparse-reward settings, a learned critic can inject estimation noise that
Abstract:
arXiv:2604.19485v1 Announce Type: cross Abstract: Reinforcement learning (RL) for LLM post-training faces a fundamental design choice: whether to use a learned critic as a baseline for policy optimization. Classical theory favors critic-based methods such as PPO for variance reduction, yet critic-free alternatives like GRPO have gained widespread adoption due to their simplicity and competitive performance. We show that in sparse-reward settings, a learned critic can inject estimation noise that