Building Controllable, Debuggable LLM Workflows at Scale
📰 Medium · AI
Learn to build controllable and debuggable LLM workflows at scale using a layered orchestration architecture
Action Steps
- Design a layered orchestration architecture for LLM workflows
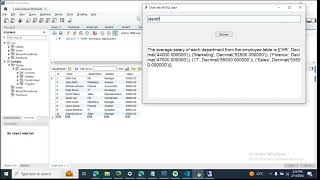
- Implement persistent memory to store model states and intermediate results
- Configure selective forgetting to manage model complexity and reduce memory usage
- Train and deploy 14B local models to improve model accuracy and reduce latency
- Test and debug LLM workflows using logging and monitoring tools
Who Needs to Know This
Machine learning engineers and data scientists can benefit from this approach to improve the scalability and reliability of their LLM workflows, while product managers can use it to inform their product strategy
Key Insight
💡 A layered orchestration architecture with persistent memory, selective forgetting, and local models can improve the scalability and reliability of LLM workflows
Share This
🚀 Build controllable and debuggable LLM workflows at scale with layered orchestration architecture! 💡
Key Takeaways
Learn to build controllable and debuggable LLM workflows at scale using a layered orchestration architecture
Full Article
How a layered orchestration architecture — with persistent memory, selective forgetting, and 14B local models — gives you production-grade… Continue reading on Medium »