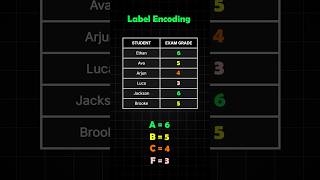
A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas…
📰 Medium · Machine Learning
Learn to clean and preprocess messy datasets using Pandas with a step-by-step guide, improving data reliability and machine learning model accuracy
Action Steps
- Import necessary libraries, including Pandas, using 'import pandas as pd'
- Load a sample dataset using 'pd.read_csv()' to practice data cleaning
- Handle missing values using 'df.dropna()' or 'df.fillna()' to remove or replace them
- Remove duplicates using 'df.drop_duplicates()' to ensure data uniqueness
- Apply data normalization using 'df.apply()' to scale values consistently
Who Needs to Know This
Data scientists and analysts benefit from this guide to ensure high-quality data for analysis and modeling, while data engineers can use it to streamline data preprocessing pipelines
Key Insight
💡 Proper data cleaning is crucial for reliable analysis and accurate machine learning model results
Share This
Clean your data with Pandas! Learn how to handle missing values, duplicates, and outliers with this step-by-step guide #datascience #pandas
Key Takeaways
Learn to clean and preprocess messy datasets using Pandas with a step-by-step guide, improving data reliability and machine learning model accuracy
Full Article
Title: A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas…
URL Source: https://medium.com/@artalha18/a-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316?source=rss------machine_learning-5
Published Time: 2026-04-18T02:04:27Z
Markdown Content:
# A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas (Step-by-Step Guide) | by Talha Abdul Rauf | Apr, 2026 | Medium
[Sitemap](https://medium.com/sitemap/sitemap.xml)
[Open in app](https://play.google.com/store/apps/details?id=com.medium.reader&referrer=utm_source%3DmobileNavBar&source=post_page---top_nav_layout_nav-----------------------------------------)
Sign up
[Sign in](https://medium.com/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=post_page---top_nav_layout_nav-----------------------global_nav------------------)
[](https://medium.com/?source=post_page---top_nav_layout_nav-----------------------------------------)
Get app
[Write](https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fnew-story&source=---top_nav_layout_nav-----------------------new_post_topnav------------------)
[Search](https://medium.com/search?source=post_page---top_nav_layout_nav-----------------------------------------)
Sign up
[Sign in](https://medium.com/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=post_page---top_nav_layout_nav-----------------------global_nav------------------)

# A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas (Step-by-Step Guide)
[](https://medium.com/@artalha18?source=post_page---byline--3f62f29e8316---------------------------------------)
[Talha Abdul Rauf](https://medium.com/@artalha18?source=post_page---byline--3f62f29e8316---------------------------------------)
Follow
2 min read
·
1 hour ago
[](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fp%2F3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&user=Talha+Abdul+Rauf&userId=0be2ae45f363&source=---header_actions--3f62f29e8316---------------------clap_footer------------------)
[](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fbookmark%2Fp%2F3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=---header_actions--3f62f29e8316---------------------bookmark_footer------------------)
[Listen](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2Fplans%3Fdimension%3Dpost_audio_button%26postId%3D3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=---header_actions--3f62f29e8316---------------------post_audio_button------------------)
Share
Press enter or click to view image in full size

## Introduction
Real-world datasets are inherently messy missing values, duplicates, inconsistent formats, and outliers are standard challenges.
Without proper data cleaning, your analysis becomes unreliable and machine learning models produce inaccurate results.
This guide provides a **step-by-step workflow for cleani
URL Source: https://medium.com/@artalha18/a-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316?source=rss------machine_learning-5
Published Time: 2026-04-18T02:04:27Z
Markdown Content:
# A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas (Step-by-Step Guide) | by Talha Abdul Rauf | Apr, 2026 | Medium
[Sitemap](https://medium.com/sitemap/sitemap.xml)
[Open in app](https://play.google.com/store/apps/details?id=com.medium.reader&referrer=utm_source%3DmobileNavBar&source=post_page---top_nav_layout_nav-----------------------------------------)
Sign up
[Sign in](https://medium.com/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=post_page---top_nav_layout_nav-----------------------global_nav------------------)
[](https://medium.com/?source=post_page---top_nav_layout_nav-----------------------------------------)
Get app
[Write](https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2Fnew-story&source=---top_nav_layout_nav-----------------------new_post_topnav------------------)
[Search](https://medium.com/search?source=post_page---top_nav_layout_nav-----------------------------------------)
Sign up
[Sign in](https://medium.com/m/signin?operation=login&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=post_page---top_nav_layout_nav-----------------------global_nav------------------)

# A practical guide to data cleaning, preprocessing, and handling messy datasets using Pandas (Step-by-Step Guide)
[](https://medium.com/@artalha18?source=post_page---byline--3f62f29e8316---------------------------------------)
[Talha Abdul Rauf](https://medium.com/@artalha18?source=post_page---byline--3f62f29e8316---------------------------------------)
Follow
2 min read
·
1 hour ago
[](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fvote%2Fp%2F3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&user=Talha+Abdul+Rauf&userId=0be2ae45f363&source=---header_actions--3f62f29e8316---------------------clap_footer------------------)
[](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2F_%2Fbookmark%2Fp%2F3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=---header_actions--3f62f29e8316---------------------bookmark_footer------------------)
[Listen](https://medium.com/m/signin?actionUrl=https%3A%2F%2Fmedium.com%2Fplans%3Fdimension%3Dpost_audio_button%26postId%3D3f62f29e8316&operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40artalha18%2Fa-practical-guide-to-data-cleaning-preprocessing-and-handling-messy-datasets-using-pandas-3f62f29e8316&source=---header_actions--3f62f29e8316---------------------post_audio_button------------------)
Share
Press enter or click to view image in full size

## Introduction
Real-world datasets are inherently messy missing values, duplicates, inconsistent formats, and outliers are standard challenges.
Without proper data cleaning, your analysis becomes unreliable and machine learning models produce inaccurate results.
This guide provides a **step-by-step workflow for cleani